












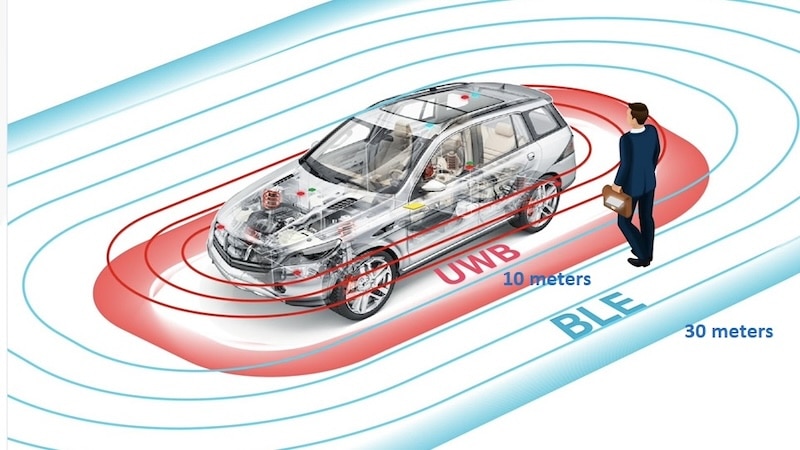




工研院在2016年9月與NVIDIA簽署合作備忘錄,近期已在自動駕駛的深度學習上,有了初步成果。為使台灣落實技術自主化,該自動駕駛車的關鍵技術皆是由工研院所自行開發,晶片組方案則採用NVIDIA DRIVE PX2,融合不同感測器的數據,使車輛具備多種感知能力,因此得以充分應付複雜的行車環境及角落。
工研院機械所正研究員/自駕車複雜環境資料融合感知技術計畫主持人連豊力指出,由於工研院所開發的自駕車,是從零開始打造,其採用的車用電腦、通訊協定,都是掌握在工研院手中,因此要做任何的操控、控制都不會有問題。現階段我們進行開車場景的錄製,完成後將資料丟到NVIDIA DRIVE PX2超級電腦開發平台中,去對應車用資料庫,以進一步推論出所拍攝到的場景是汽車、巴士車,還是行人等。然而,當比對程度達到水準後,就能進一步將車外場景的主要目標對象框出來。
當系統須一邊開車一邊進行學習,其處理耗能會相當高,但當學習完成後,單純進行辨識的耗能則會降低很多。因此一般在自駕車的學習階段,會是用離線的方式進行學習,而學習完後的辨識,則就可用在線的方式來進行。但若辨識不成功,則又會再送回資料庫去做學習。連豊力表示,未來自駕車的發展,很可能會是讓車上使用車上處理器,並直接做現場的處理與篩選,但在一段時間後,仍會上傳到資料庫,以便做比對。
連豊力進一步表示,目前自駕車的開發單位在運用感測器去感測外界訊息上,主要有兩個做法,第一種方式是比較傳統的,運用感測器所能感測的類比訊號,例如根據車道線是白色還是黃色,去做電腦視覺分析,也就是從色彩、幾何去累積物件的特徵,其可靠度較高,目前所看到的行車紀錄器或辨識系統,大多是運用這樣的方式在做。
連豊力進一步表示,另外一種做法,則是目前NVIDIA主要在採用的方式,由於每一次開車左右兩邊的場景,會有所差異,尤其是當道路並非高速公路般筆直,而是彎曲的時後,若要讓一台車學會如何開車,便必須透過錄影機與電腦,將開車的場景、指令(左轉、右轉、不動、煞車、加速等)錄下來,紀錄完成後,電腦就會開始推論,當影像場景右邊比較亂、左邊比較清楚時,代表方向盤正在左轉,而影像如果很平均,則代表方向盤沒有在動等,進而去找出中間的關聯性。
連豊力分析,當這樣的關係被找出,電腦就可以進而去判斷,主人的開車狀況,甚至車子該如何進一步自動進行左轉、右轉。因此當電腦的影像紀錄越多,自動駕駛能使用的資料庫也就更為豐富。不過相較於傳統方式,其可靠度是比較低的,因其並沒有辦法做到1對1對應,當學習中的攝影機沒有拍到某些資訊,這些資訊就學習不到了,也就無從判斷,因此如何讓機器的感測能力全面提升,將會是自駕車須跨越的一大門檻。
有鑑於此,目前工研院在發展自動駕駛時,是兩種方式同步進行。由於圖形、影片的資料量相當大,而NVIDIA最大的強項即是在前端的GPU影像處理,這也是工研院與NVIDIA聯手合作的原因。





