

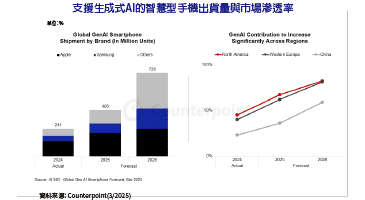
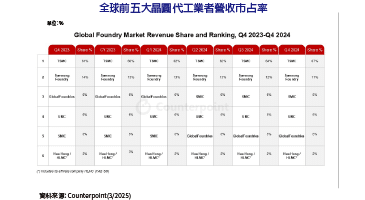
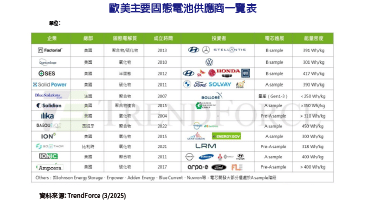


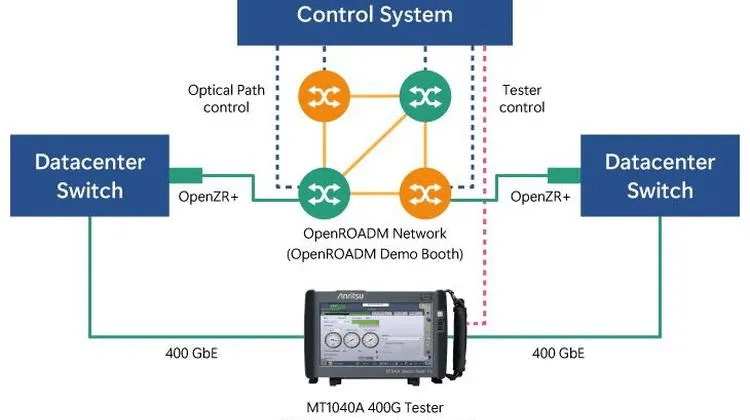


各大廠爭先搶攻邊緣運算大餅,FPGA技術在延遲性上的領先優勢,不容小覷。首先,在DDR記憶體處理上,本身就與傳統架構有所不同,以致於延遲可以降到很低。除此之外,該技術在SoC的批次處理(Batch)架構也相對較小,因此得以兩方面降低延遲。這樣的特性,促使了FPGA十分適合用來滿足伴隨5G而來的各種高即時類型應用。
賽靈思(Xilinx) ISM行銷資深技術經理羅霖表示,邊緣運算是大勢所趨,同時也是物聯網進一步的演進,閘道器是匯集許多感測器的平台,其會對收集來的資訊進行處理與分析,而若再進一步將處理、分析、通訊能力做整合,即屬於一種邊緣運算的單元。
羅霖進一步表示,隨著物聯網、人工智慧的推進,邊緣運算很有可能會因晶片表現的增強、晶片的成本下降,部署得越來越多。賽靈思旗下的Zynq SoC成本,相較於三年前,已降低了一半的成本,這樣的成本降低與28nm先進製程有所關聯,也因其出貨量越來越大,使得晶圓成本,以及晶片所分攤的封裝測試成本隨之降低,而未來也很有機會持續下降。
過去賽靈思主要是以無線通訊領域為主,近兩年開始在數據中心取得很大的進展。數據中心主要針對具體的工作量(Workload)進行加速,也就必須挑選適合的處理器,像是GPU、FPGA等。
羅霖分析,在挑選數據中心的處理器時,延遲性(Latency)是相當重要的,而FPGA這樣的架構,就相當有優勢。GPU要達到比較好的性能,就得用比較大的Batch,處理器必須輸入許多數據進行運算,而FPGA的Batch是比較小的,僅須1~2個Sample就可進行運算,但GPU則要等到20個Sample後,才能形成Batch進行運算,也就讓FPGA在延遲性上大為勝出。
若將Zynq SoC的reVISION流程,對比NVIDIA Tegra X1的效能量測數據,即可看出在機器學習方面,每秒瓦特影像的數據高出6倍,電腦視覺處理的每秒幀數高出42倍,而延遲(以毫秒為單位)卻只有五分之一,這點對各種即時應用而言至關重要。
舉例而言,一部汽車搭載以賽靈思基於Zynq SoC的reVISION技術,對照另一部搭載NVIDIA Tegra元件的汽車,比較兩者在辨識潛在碰撞危險與制動煞車的表現。在時速65英哩下,依照NVIDIA元件實際建置方式,賽靈思在反應時間方面的優勢,讓距離縮短5至33英尺,以輕易實現安全煞停並避免撞車。
此外,羅霖也提到,在數據中心有另一項全新需求,目前也越來越普遍。客戶希望在一塊板卡上,可以同時支援神經網路加速、通訊等功能,而現只有FPGA能通過可編程,將加速卡晉升為深度學習的加速卡、100G的通訊板卡。這除了可以節省成本,也讓部署管理變得更加容易。