












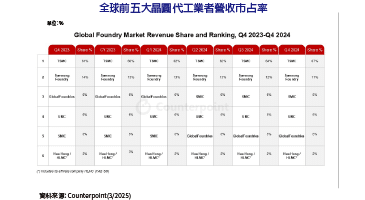
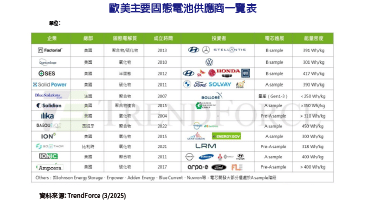




人工智慧戰火擴大延燒。物聯網(IoT)方興日盛,聯網裝置與數據資料爆發成長,在此情況下,同時又要保障低延遲、安全與個人隱私等要素,促使人工智慧機器學習應用從雲端轉移至邊緣。為了讓機器學習技術能在邊緣端能充分發揮所長,安謀國際(Arm)近期在北京舉辦Arm Tech活動,提出三大機器學習(ML)晶片設計要點,加速人工智慧產業發展。
Arm顧問工程師暨機器學習事業部技術總監Ian Bratt表示,該公司認為專用型機器學習晶片須具備幾項特點,包含高效能卷積(Efficient Convolutions)、高效能數據移動(Efficient Data movement)與可編程/彈性(Programmability/Flexibility)等關鍵技術。
Bratt談到,該公司調查透過機器學習處理大量工作量時,大多都圍繞著卷積處理打轉,因此要提高整體機器學習效率,卷積處理效率的提升是非常關鍵的一環。再者,在功耗設計部分,Arm發現晶片中數據移動所損失的功耗,大於處理每個位元數據本身,換言之,高效能數據移動是影響功耗的關鍵點,也為機器學習第二大設計要素。最後,由於人工智慧為全新領域,神經網路技術在不斷變化,迎合此趨勢,具備可編程與彈性的設計不可或缺。
綜合上述的設計概念,Bratt認為,以Arm現有的處理器IP,著實難以負荷人工智慧與機器學習所需具備的特點。為此該公司抱著從零開始的決心,針對人工智慧和機器學習應用打造全新處理器。
但Bratt也強調,從零開始設計並非捨棄該公司在CPU和GPU處理器方面累積的優勢,相反的,而是將這些優勢融入於全新的機器學習專用晶片。例如延續Arm在CPU具備的可編程優勢,以及GPU數據處理壓縮能力和高吞吐量的設計特點,將其整合至機器學習晶片設計之中。
整體而言,Arm機器學習處理器專為機器學習重新打造,其基於可高度擴充的Arm機器學習架構,期能為機器學習應用達到最高的效能與效率。初期第一代機器學習晶片聚焦於行動運算市場,其提供每秒超過4.6兆次運算。透過智慧資料管理,每秒兆次運算(TOPs)在現實使用情況下的有效處理量可進一步提升2~4倍;此外,在溫度與成本限制較多的環境下,提供以每瓦每秒超過三兆次運算(TOPs/W)的效能與效率。





