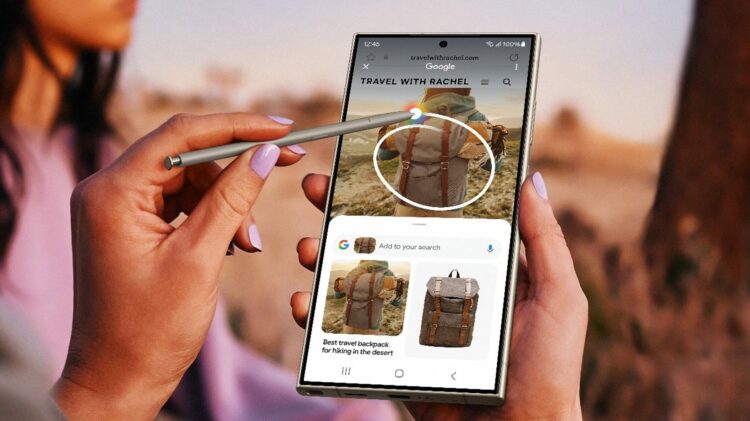






舉例而言,如繁瑣的資料庫整理、閱讀查詢等等工作,都與語意分析有關係。另外,電子商務中的輿情分析,也是語意理解技術一項相當重要應用實例。儘管語言相關的應用依然是人工智慧中比較困難的一部分,然而目前在輿情分析應用中,準確率已可達到八成以上。雖距離完全正確尚有距離,但已經可以做到相當程度的應用。
與輿情分析概念相同的意圖偵測功能,同樣可以應用在線上客服機器人的開發,或是自動翻譯機制,都是人工智慧中的語意理解技術能夠發揮的應用領域。
中文編碼無法窮舉 須轉向機器學習技術編碼
語意理解的第一個步驟是為文字編碼。例如,英文屬於拼音文字,26個字母加上標點符號頂多70個編碼就能涵蓋英語的所有編碼可能。但中文的變化不如英語穩定,同樣一件事情有無限多種表述方式,因此在中文的語意理解操作上,就會相較英語困難許多。
若是將每個中文字看作單獨的存在並個別編碼,大約會有兩萬個以上的編碼數據。由於相較於英文而言,中文若是將幾個單字抽換、交換位置,人類依然可以理解,要是再加上網路流行語、同音字、中英文夾雜等等使用情境,編碼數可能將會超過四萬。
先前曾針對電子商務的評論進行分析,發現同樣是在表示「快遞速度優良」此一訊息,就有超過三千種中文表述方式。而且表述方式還能夠無限擴充,該資料量將隨著數據的增加而出現無限多種中文句型(圖1)。

以往,傳統語意分析方法是必須先建立一個巨型的資料庫,接著用抓關鍵字的方式比對出需要的資料,並沒有使用到深度學習技術。然而,由於語言很複雜且具彈性,因此使用窮舉法建立資料庫將會發現永遠無法列出所有可能。唯有轉向讓機器理解,以新的角度理解中文的語意理解,才能做到最具效率且準確的語意理解。
配合詞向量技術 以機器視覺技術理解語意
以往人們皆是以序列的方式去思考文字,進而理解語意。近來人們開始將技術開發方式轉移至詞向量技術。由於其能自主學習,進而找到中文字詞之間關聯的特性,故成為近來中文語言分析的最大突破。
利用詞向量的特性,把百萬個詞彙壓縮成兩百個維度,會發現語言突然變得很簡單,只要使用基本的加法、減法數學概念,便能夠解決語意之間的關聯性。舉例而言,「國王」、「皇后」、「男人」、「女人」四個字詞都能夠指向一個向量,因此,假如我們輸入「國王-男人+女人」,電腦便能計算向量之間的相似度,而得出「皇后」此一解答。詞向量的計算方式大致如圖2。
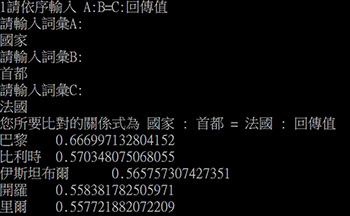
也由於每個字詞都有一個向量,該向量也能被視為是一個二維的圖像。因此又進一步衍伸出一個新的技術趨勢,便是將機器視覺技術運用於語意理解之中。也就是說,以前會去偵測序列的意義,現在是去偵測該二維圖像的意義。
利用機器視覺技術處理語意理解將會有效提高運算速度。以往利用序列的方式,一次只能運算一個字詞的維度,無法平行運算。然而機器視覺能利用GPU平行運算,將比傳統運算方式更為精準且效率更好。