

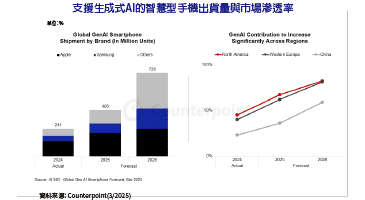
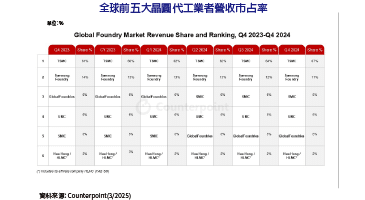
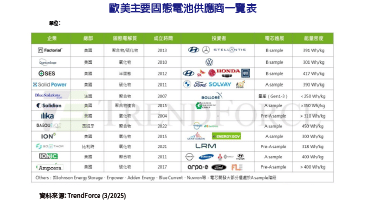

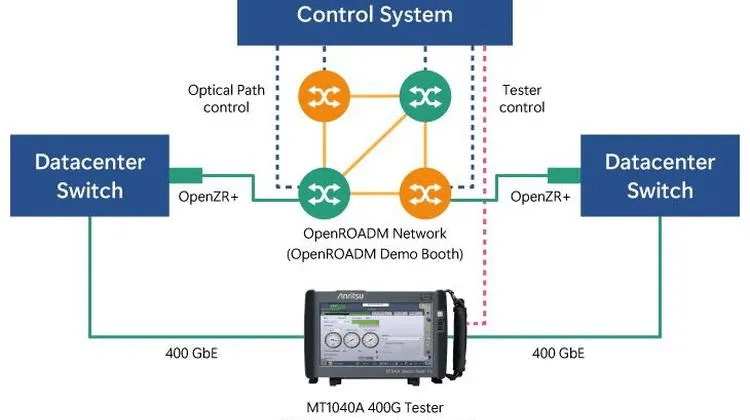



語音操作躍居智慧家庭人機介面新星。亞馬遜(Amazon)語音助手Alexa無孔不入穿梭於2017年國際消費電子展(CES)大展,隨處可見的電視、冰箱、空調和洗衣機等智慧家電,甚至是陪伴型機器人皆已導入語音操作功能,堪稱智慧家庭的殺手級應用。
工研院通訊系統研究部經理葉恆芬表示,相較於2016年的CES展會,大多智慧家庭還是圍繞著以手機作為控制中樞,遙控家中大小各種智慧裝置的局面。繼Amazon於2016年開放出Alexa應用程式介面(API)後,吸引各大廠商相繼導入語音辨識功能。至今,Alexa已具備七千項技能,一百八十家供應商在此平台開發出商品,極可能成為跨平台統一的呼叫方式。
葉恆芬分析,語音介面成長的驅動因素主要有三點,一、語音辨識錯誤率的下降,語音辨識若在85%以下,則不符合導入產品的標準,語音辨識率需達95%以上才具備應用於終端終置資格,以現階段來說,目前的語音辨識率已高達97~98%以上,與人類辨識語言的準確率相似;二、行動語音助理使用量提高,現在很多的語音請求來自於行動裝置,以美國用戶而言,目前已有20%的手機用戶以語音型式發起數據服務的請求,舉例來說,Google Now的語音搜尋成長達35倍之多;三、語音平台的API開放,設備、內容與應用程式相繼導入,使得語音計算將有機會成為物聯網裝置主流的輸入型態。
事實上,在智慧家庭領域已陸續出現以人工智慧(AI)晶片為基礎,結合語音和影像辨識技術的功能,以提高物與物之間溝通(Device to Device)的創新,例如樂金(LG)已有多項家電產品導入語音、影像辨識為基礎的深度學習演算法,並與開放網路基金會(ONF)、Google和Amazon策略合作,以提高產品互通性。
然而,當前的語音辨識系統大多還會受到背景雜音的干擾,說話的腔調、方式甚至是不同品牌設備連結等因素,也會影響語音辨識的準確率。有鑑於此,葉恆芬認為,下一階段語音辨識精進的方向,可朝降低背景雜音干擾、自然辨識說話者語調和某些專用術語(Lingo)的辨識與學習發展。
工研院產經中心電子與系統研究組零組件研究部經理林澤民補充,除了語音辨識功能之外,NVIDIA CO-Pilot具備語音、臉部識別與唇形辨識三合一的多重辨識能力,可更加精準辨別使用者表達的指令,這種多重辨識的人機介面技術,強化識別的準確性與安全性,將成為未來人機介面發展的趨勢。