














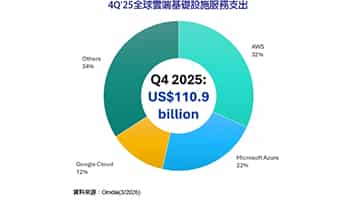
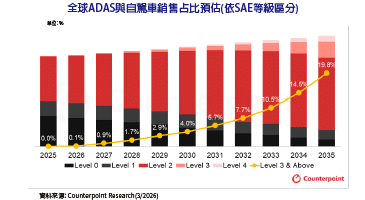
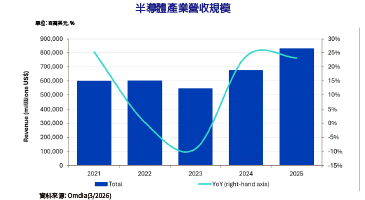
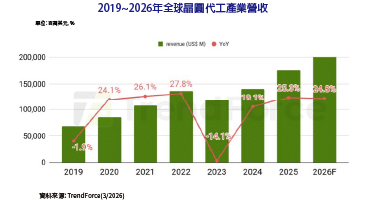





在2020年最後一天,一份由超微(AMD)申請的GPU Chiplet專利正式公開,在業內引發許多討論。利用先進封裝技術將多枚Chiplet整合在同一片載板或封裝體中,已經不是新聞,但以Chiplet實現GPU的難度特別高。由於GPU的平行運算程度遠高於CPU,要在不同Chiplet上實現平行化,技術難度更高,且不同Chiplet上的記憶體要達成同步,通訊成本也會變得更昂貴。因此,超微這篇以被動式Crosslink矽中介層實現GPU Chiplet的專利,引起業界矚目。
超微在標題為《GPU CHIPLETS USING HIGH BANDWIDTH CROSSLINKS》的專利申請文件上開宗明義寫道,以傳統單一裸晶(Monolithic Die)方式設計的晶片,製造成本正變得越來越昂貴。因此,其他型態的處理器,例如CPU,已陸續改採Chiplet概念,並成功地協助晶片商達成降低製造成本、提高良率的目標。由於CPU運算本質上有比較高的異質性(Heterogenoeus),因此把多個CPU核心分別放在不同晶片上,是比較自然的作法,Chiplet間的通訊挑戰也比較容易克服。
但GPU的運作型態並非如此。GPU處理的運算任務不僅高度平行化,而且不同工作階段間的順序必須同步。因此,GPU編程模型如果把工作階段分散到不同的執行緒,由於很難妥善地實現平行化,其效率往往會變差,且實現記憶體內容同步所需付出的通訊成本,也會十分昂貴。此外,從應用編寫的角度,即便GPU是內含大量核心的處理器,在編寫應用程式時,還是將所有GPU核心視為一個個體。上述因素使得GPU架構要採用Chiplet概念,變得更加困難。
因此,如何降低GPU Chiplet之間的通訊成本,並提供足夠的通訊頻寬,成為GPU Chiplet能否從概念走向現實的關鍵。超微的研發團隊提出了使用被動裸晶來橋接不同GPU Chiplet的作法(圖1),並指出這種方法可以保留現有的GPU編程模型,同時又讓GPU的性能有所提升。在超微所提出的架構中,GPU Chiplet陣列的第一個Chiplet可藉由匯流排與CPU通訊,第二個GPU Chiplet則是透過被動Crosslink與第一個GPU連接起來。被動Crosslink是一片被動的中介層裸晶,專門用來實現Chiplet之間的通訊。

熟悉半導體封裝技術的讀者,可能會覺得超微在專利申請書裡提供的這張圖片,似乎跟台積電的InFO_LSI(圖2右)十分相似。有IC設計業者指出,考慮到超微目前在台積電投片生產,或許超微的這項專利技術,與台積電的InFO_LSI有密切關係。

無獨有偶,超微在GPU市場的主要競爭對手–NVIDIA跟英特爾(Intel),也都對Chiplet概念有些探索。英特爾已表示,其針對資料中心設計的GPU會藉由EMIB與Foveros實現GPU跟HBM記憶體間的互聯,至於會不會用封裝技術來連接多顆GPU,尚不清楚;NVIDIA亦曾發表過用4枚GPU Chiplet組合成GPU的研究成果,但NVIDIA的Hopper架構會不會採用這種做法,亦未可知。
或許可以很保守地說,即便GPU Chiplet在技術上不易實現,但相信目前市場上主要的GPU供應商,都已經看到GPU設計分割的可能性,並肯定有所準備。





