










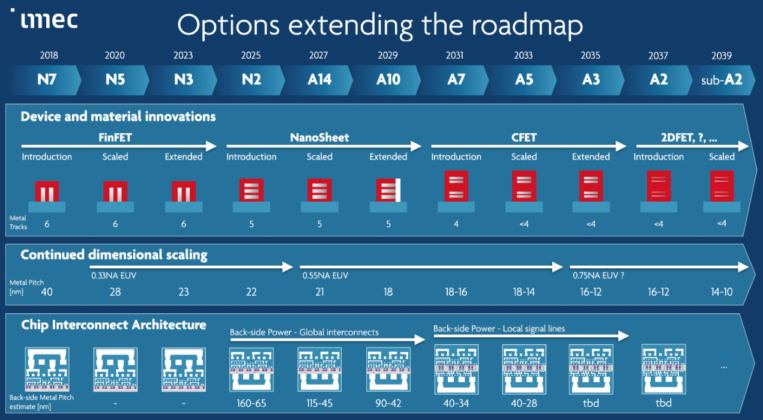


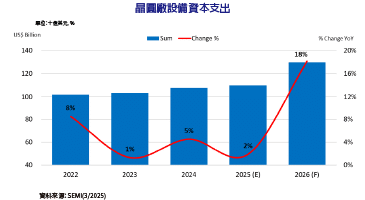
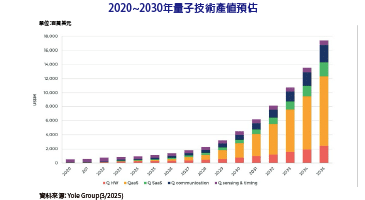
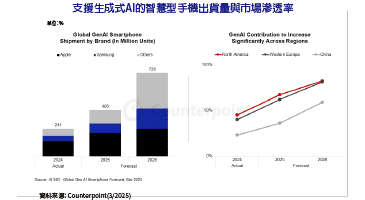




在邊緣運算裝置上執行人工智慧(AI)演算法推論,將讓人工智慧應用的布署更具彈性,是未來科技發展的大趨勢。相較於CPU、GPU等處理器,FPGA在執行人工智慧推論時的功耗/運算效能比表現最為優異,在人工智慧從雲端往邊緣擴散的過程中,將扮演重要角色。
萊迪思半導體產品行銷經理Jatinder P. Singh表示,機器學習技術在推理過程中的表現,主要取決於訓練資料的數量和品質,以及在沒有被編程的情況下,學習演算法的優劣。例如,若要打造一個可以準確區分狗和貓的智慧型機器,在訓練階段,要被輸入成千上萬狗和貓的圖像,直到它能夠準確識別狗和貓。
一旦訓練完成,這樣的機器即可迎接真實世界的挑戰,以推理(識別)狗或貓,儘管機器從未真正看過某一特定的狗或貓的圖像。但對於機器而言,重點在於輸入的資料,是否能夠準確表達狗和貓的形象,並能夠支撐它在推理階段獲得正確的結果。
Singh指出,卷積神經網路的本質是不對機器進行明確的編程,而是讓其經過訓練,然後實現學習/行動,因此其可基於邊緣應用資料進行推理。訓練通常使用高性能CPU、GPU、FPGA和/或TPU(Tensor Processing Unit),並使用所需的浮點數來表示海量的資料。因此會是在雲端/數據中心進行訓練,在邊緣裝置進行推理。
為讓人工智慧成為主流,機器學習已經到了讓機器智慧化發生質變的關鍵點。在FPGA中實現ANN、BNN和CNN的演算法,便可發揮關鍵作用。此外,介面標準變得更高速並且更智慧,也讓很多資料不再須要發送到雲端進行推理。
Singh進一步表示,使用本地端運算資源來提升性能是至關重要的。在邊緣裝置實現推理功能,可以最大限度地減少分析過程導致的延遲,而非透過網路將所有資料發送到數據中心來進行分析。這同時也可降低網路壅塞,增強使用者隱私保護(因為資料存儲在本地設備上),且在沒有網路連接的情況下,即可啟用推理功能。
此外,在邊緣裝置實現推理功能,還可降低網路壅塞,增強使用者隱私保護(因為資料存儲在本地設備上),並且可在沒有網路連接的情況下啟用推理功能。若與CPU和GPU相比,FPGA能憑藉平行處理架構,以最低的功耗實現最高的每秒運算(OPS)量,因此非常適合用於邊緣推理應用。





