





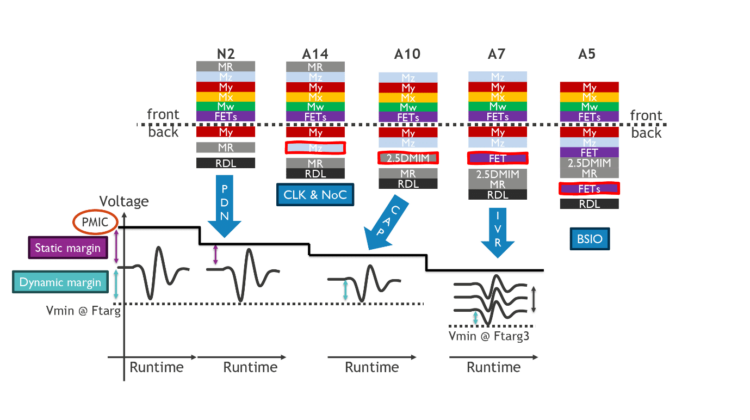

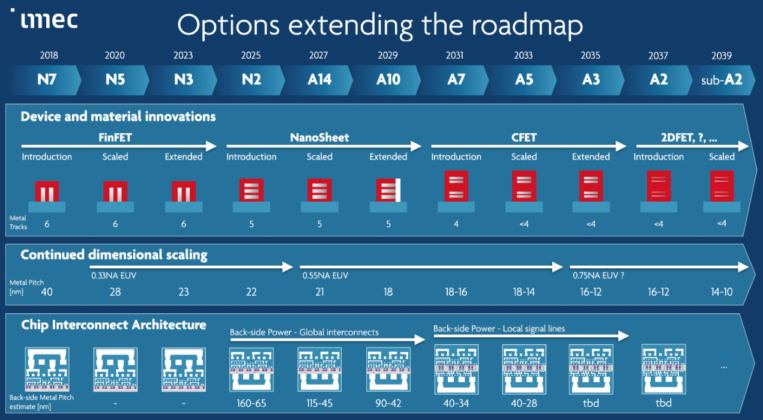
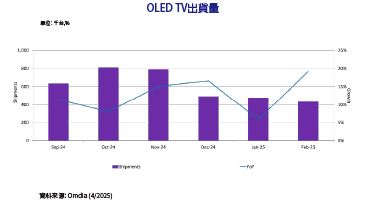
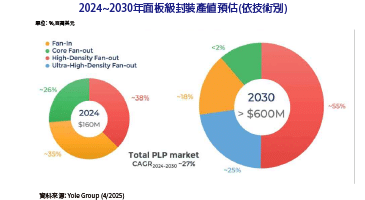



GPU影像渲染技術升級 光線追蹤應用開發更輕鬆
但是,這些日常生活中習以為常的效果,必要耗費龐大的資源才能在逐線掃描的渲染(Scanline Rendering)環境中實現。因此,業界正亟需一種實際且具成本效益的方式,以便能輕鬆取得即時的光線追蹤效果。
可惜的是,截至今日,就運算和系統成本來看,光線追蹤效果幾乎僅限於離線渲染,或是必須採用非常昂貴且缺乏互動性的高功率系統,才能實現即時渲染功能。事實上,業界一直在等待實際的光線追蹤技術出現,也因此去年在美國Anaheim市舉行、深具影響力的Siggraph研討會中,光線追蹤議程標題還被戲稱為「光線追蹤就在未來,遙遠的未來」。
但這一年以來,技術進展已有了重大改變!如今市場上已出現一種嶄新、完備的即時互動的光線追蹤技術,不但能解決這些問題,並可針對遊戲機和行動消費裝置等廣泛應用提供一套可擴充且具成本效益的解決方案。
光線追蹤首重渲染系統設計
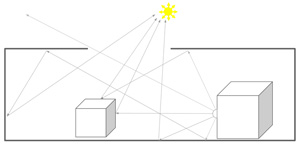
光線追蹤的處理流程很簡單:當模型被轉換到世界空間(World Space)裡面(會利用3D座標系統來執行模型的動畫與操作),一個檢視區域(Viewport)會被定義,然後光線便會從相機並透過Viewport中的每個畫素位置進行追蹤,一直到被模型所占據的空間與最接近的物體相交為止。主要光線(Primary Ray)會決定物體從相機視角的可視性,假設物體和光線有交會,就會產生三條或更多新的光線,包括反射、折射及每個光源的照明光線。
然後,這些次要光線(Secondary Ray)會被追蹤和彼此交錯,並產生新的光線,一直到與光源交會,或是遇到其他的限制為止。每次反彈,都會為物體表面帶來一種顏色,並被加到累積緩衝器中;當所有光線都被解析完成,緩衝器內就會包含最終的影像(圖1)。
 |
| 圖1 光線追蹤可建構光線在場景中傳輸的模型 |
一旦模型建立,並定義材料特性和放置光源後,所有的照明效果會此在渲染過程中自動產生。
這個過程與在掃描線渲染器中所產生每一畫素真實的照明效果方式完全不同。在掃描線渲染器中,由於世界空間模型在片段渲染開始前便放棄不用,因此所有的照明效果都必須在內容建立過程中擷取,並製成稱為光照貼圖(Light Map)的特殊用途紋理,然後此紋理會被用來將預先計算好的光照值疊放至物件表面上。
雖然,原則上是有可能以內建的預處理步驟來動態地產生光照貼圖,而且也有實際的例子存在,但為了保留可用的運算資源以供其他的渲染效果使用,即時應用通常都是採用預先製作的方式。舉例來說,必須在互動系統中動態運算所得的陰影,通常都是藉由須要以多步驟處理場景幾何的方式來進行,以便能產生陰影貼圖,它的用法與光照貼圖類似,都是在最後的渲染步驟中才會被貼上。
此種作法除了耗費運算資源外,還有許多的缺點。由於它須要預測會用到哪些貼圖,並將其視為遊戲資產予以保留,因此會增加執行應用程式所需的資料大小。除了這些問題外,貼圖是利用有限數量的固定解析度所產生的,因此會有常見的解析度問題。
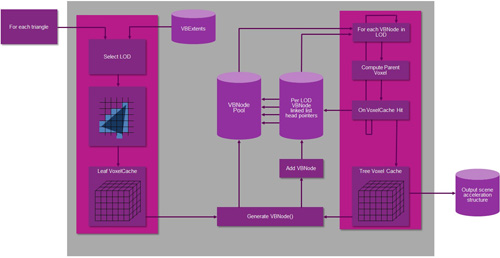
要讓光線追蹤技巧能為一般的應用所採用,必須將一些類似光線追蹤的技巧使用在現今的內容產生中介軟體套件內的離線光照貼圖製作過程中。它們可被用來產生光照貼圖製作的輸入影像,並提供一種在OpenGL和DirectX等既有的即時渲染系統中以漸進式導入光線追蹤技巧的方法,而不必放棄整個原有的架構系統(圖2)。這當然是有益的,因為現有的工具與執行時期(Runtime),以及所有開發人員已經知道的先進技巧都能被保留與增強,能為此較新的技巧提供一個衝擊最小的移轉路徑。
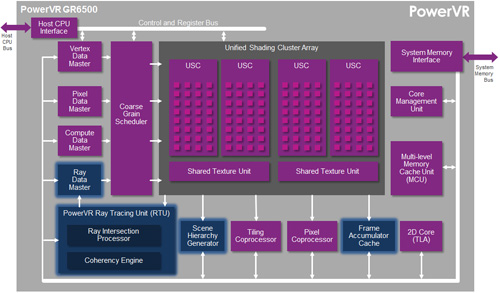 |
| 圖2 PowerVR GR6500方塊圖 |
這能透過將新功能加入Runtime引擎使用的著色程式語言中來達成,以允許任何一種著色器程式在執行期間投射光線。渲染管線是不會改變的,它仍然是立即、逐漸增量及掃描線的渲染方式。現有的主要可視性決定方法仍可保留,但渲染系統會藉由既有的資料結構與方法來增強,以解決光線追蹤的問題。
一旦擁有這項功能,並且有足夠的Runtime效能,便能放棄預先製作的方法,以簡化應用程式開發的工作流程,同時還能顯著提升最終結果的視覺品質與動態功能。
光線追蹤引發GPU效能不足問題
今日的問題在於,缺乏足夠的Runtime效能或太過昂貴,以及互動性非常有限,特別是試圖將光線追蹤技巧應用在現有的繪圖處理器(GPU)硬體上,將會導致嚴重的效率問題。
它的主要困難點在於,目前的即時渲染系統採用螢幕空間中區域性的資料,並透過平行化來達到效能。此資料與相關執行中的任務是同步的,因此三角形中的鄰近畫素會在記憶體中放在一起,同時它們會傾向共享材料特性,使得存取紋理、著色器程式等會較有效率,並易於平行化。但對光線追蹤系統來說並不是如此,在此系統,中視覺上相鄰的物件可能會在世界空間座標系統中離得很遠,而且光線通常會因為連續反彈而發散,所以,當採用基於GPU的方法運作時,是非常沒有效率,而且不切實際的。
沿用既有的資料結構還有另外兩個問題:建構和穿越(Traversal)。互動式動畫須使用的加速結構(通常是體素化樹狀結構,亦即Voxelized Tree)要能即時更新,然而目前的更新方法不僅慢,而且可能非常昂貴。同樣地,須採用輕量的穿越法,以將從加速結構中取回資料的時間最小化。以下將提出解決這三種問題的解決方案,並說明如何利用新一代GPU矽智財(IP)核心來建置這些技巧。
由於主要目標是把光線追蹤功能帶到標準的GPU中,因此須要考慮GPU中的基本架構。市場上有許多種GPU,特別是在低階市場,但一般來說,GPU著色單元都包含單指令多重資料(SIMD)的計算邏輯單元(ALU)陣列。在ALU中,任務(也就是一組的運算作業)會透過排程器來分配執行。這些運算,在Imagination的PowerVR架構中被稱為實例(Instances),被用來使它們共享一致性(Coherency)特性的程度達到最大化,諸如空間區域性(Spatial Locality)、材質特性等,以便從記憶體擷取特性資料的效率,以及它們在跨SIMD陣列執行的平行效率都能最大化。
克服光線追蹤挑戰 GPU新增一致性採集單元
在PowerVR架構中,這些陣列會被分組為不同的統一著色叢集(USC)。掃描線渲染過程會自然產生高度的一致性,所以陣列會持續忙碌地作業,而ALU的延遲和不可避免的記憶體存取的延遲能透過任務的切換來降低。有許多資料主機(Data Master)會饋送到排程器中,以處理頂點、畫素和運算相關的任務,一旦著色運算完成,結果會輸出到資料接收器(Data Sink)中,再根據渲染管線中哪一部分會被執行來進一步處理(圖3)。
 |
| 圖3 Mads Drøschler利用PowerVR光線追蹤技術所製作的影像 |
光線追蹤單元(RTU)能加入此清單中,以同時做為資料接收器(Data Sink)和資料主機(Data Master),所以它能同時接收來自著色器的新光線查詢,並將光線/三角形交錯的結果發配回去,以供著色之用。它包含儲存大量的完整光線查詢(含使用者資料)的暫存器,其附加在「軸向包圍盒(AABB) vs. 光線」測試器和「三角形 vs. 光線」測試器等固定功能的SIMD陣列上。
重要的是,這裡有一個一致性採集單元(Coherence Gathering Unit),能把記憶體的存取要求組合到兩種類型的其中一種的一致性序列:交叉序列和著色序列,然後將其排程處理。交叉序列會排程至SIMD AABB或三角形測試器;著色序列則會送到USC。
交叉序列在運作時會一面生成、同時一面破壞,這代表著一連串同體系的包圍體階層(Bounding Volume Hierarchy, BVH)的節點或三角形會從外部記憶體串流進來。一開始,這些序列通常都是完整的,因為原始BVH節點橫跨場景中的大體積,因此大部分的光線都會持續撞擊到它們。當光線的完整序列會從階層的底部開始測試時,底部節點會從記憶體中被讀取,而硬體會與適當的節點和三角形進行交叉光線。
對於每個撞擊的節點,新的交叉序列會動態地產生,而撞擊到節點的光線會被放到新的子序列內。如果子序列完全滿了(這在BVH上經常會發生),它會被推到一個已經準備好的堆疊中,並立即被處理。如果序列不完整(會發生在樹狀的較深處,特別是來自USC的散射輸入光線),它會被保留在序列快取內,一直到在相同的BVH上有更多的撞擊發生為止。在此模式中,序列能有效地代表在動態隨機存取記憶體(DRAM)內的位址,以便未來能開始讀取。此作法有一致性採集光線到三維(3D)空間區域的效果,並能動態地在較不容易進行一致性採集的場景區域內消耗這些序列。
此過程會一直以串列的方式持續進行,直到光線穿越三角形葉節點(Leaf Node)為止;當光線不再是任何交叉序列的成員時,最靠近的三角形就會被找到。
這時候,就會產生新的著色序列,但此時它所採集的資料與此三角形相關的著色狀態具有一致性。一旦著色序列完整了,它就會成為一項任務,然後會被排程到著色器中去執行。變量(Uniforms)和紋理狀態會載入到共用儲存器內,著色任務的平行處理便開始執行:每個光線撞擊的結果在此任務中都代表著一個著色實例。
此行為與光柵片段著色器的行為是一樣的,但著色器具備額外的特性,其能利用PowerVR著色器指令集中新增的指令來產生新的光線,然後將它們以新的光線查詢送到RTU。
確保一致性採集作業 GPU採用非阻斷式光線追蹤
確保一致性採集作業 GPU採用非阻斷式光線追蹤
由於一致性採集的關係,RTU會以其資料進入時完全不同的順序,將光線/三角形的交叉結果回傳到著色器。取決於一致性的條件,較早在訊框渲染中進入RTU的光線有可能會最後離開。
這種動態一致性採集的方式有平行化採集光線(而不是畫素)的效果,這表示,即使光線是從完全不同的其他畫素的光線樹而來,也能被收集在一起,以便能最大化場景中所有存在的可用一致性。然後,它會解耦管線,產生能高度容忍延遲的系統,並實現一個非常完整的重新排序的可能性組合。
為了使此作法能產生效果,需要在內嵌於晶片上的高速靜態隨機存取記憶體(SRAM)內保留關鍵之飛行中(In-flight)的光線。任何光線回彈都會謹慎處理,且能保留所有狀態,此種設計須採用非阻斷式(Non-blocking)的光線追蹤模式。
舉例來說,典型的深度第一(Depth First)光線追蹤著色器通常能投射一條光線,這是為了決定光線交錯後的物體的顏色。因為這是重複發生的,每條光線都會產生龐大的著色器狀態堆疊,這會使取得足夠的傳輸中光線變得不切實際,因而無法有效地執行一致性採集,而且寶貴的晶片上記憶體資源將不敷使用。
在非阻斷式的模型內,著色器會產生光線,寫出所有稍後要解析光線所需的資訊,然後將光線發送到RTU中,並且毋須等待結果的完成。然後,當光線在未來某時間點(由於RTU內的一致性採集作業仍在進行,所以無法確定)開始於著色器執行運算時,由於其所傳遞的色彩訊息,因此它會知道此光線對哪個畫素會有貢獻及其貢獻的程度。此過程會在光線樹由上而下一直重複地執行,而且著色器每次著色都可投射多條光線。其關鍵在於,原始畫素中所有發射的光線將以不同的影響因素累積回到畫素內,這些影響因素是根據反彈光線撞擊到的各個著色器來調變的。
此累積過程會發生在內嵌於晶片上的訊框緩衝累積器(FBA)記憶體中,它會快取晶片上的畫素,並有效地做用為這些畫素的運算不可分割的Atomic Read Modify Write浮點加法器。利用非阻斷方式所成功建置的渲染器會發現,只有很少數的行為無法輕鬆地適用於此模型中而已。
SHG演算法增強光柵轉化器
最後的要素是建構加速結構,此結構必須是一個完全動態的系統,能夠用來增強光柵轉化器(Rasterizer)。這是在場景階層產生器(Scene Hierarchy Generator, SHG)內執行的,其中建置了一個能以串流的方式為RTU建立BVH的演算法,並直接放在頂點著色器之後。SHG會以從下到上的方式建立AABB階層,並直接寫入DRAM中。
從內部來看,SHG將整個世界視為log2稀疏八元樹(Sparse Oct-tree)。它有空間節點的核心概念,也就是在log2 Oct-tree中的一個整數位址,亦即[xyz]和「層級」,這就是該層級立體畫素(Voxel)的log2大小。這些3D空間的整數表示法在內嵌於晶片的SRAM上會快速地重新鏈結,但直到它們重組好之前不會真的離開晶片,然後會被送出,作為AABB BVH的節點。
SHG會從頂點著色器每次讀取一個輸入的三角形,然後從樹的底部開始一直往上,以串流形式將AABB寫到DRAM中。SHG演算法是根據以下兩個假設來進行此良好的行為模式:一、以三角形相對於整體場景的大小來約略代表該區域的三角形密度;二、三角形通常是網格的成員,因此頂點著色器的遞交次序中會有一些固有的空間區域性。
利用第一個假設,SHG將比較每個三角形相對於整體場景尺寸的大小,以決定要利用哪個log2層級來將此三角形予以立體畫素化。大三角形的log2層級較低,但在樹的位置較高,而小三角形的深度較深。此外,「又窄又長」的三角形會被推到較深處,如此才能得到更精細的立體畫素,因此稍後的AABB會更有效率地包圍(Bounding)(圖4)。
 |
| 圖4 單一步驟建立加速資料結構 |
立體畫素轉化器(Voxelizer)會為從3D立體畫素的快取記憶體饋入的三角形產生節點。此快取記憶體能有效地決定三角形的空間群組–當快取有雜湊碰撞(Hash Collision)或溢出時,節點便會產生(此3D快取的方式是建立在上述的第二個假設,它實際運作的效果非常好)。
然後,這些節點會依次擁有一個計算出來的母節點位置,並再透過導入立體畫素的快取記憶體。此演算法會沿著樹狀持續執行,將群組的AABB寫到DRAM中,以供RTU之用。
加速實現光線追蹤 混合式渲染技術受青睞
從繪圖開發人員的角度來看,如果能夠保留所有目前使用的開發流程,包括工具和應用程式介面(API),才能將採用光線追蹤的技術障礙降至最低。這意味著,不應該將整個流程轉換到新的渲染方式(例如前述的主要光線可視性決定法),最好能建立一個混合式系統,此系統採用增量式掃描線演算法供可視性決定之用,但可以選擇性地加入光線追蹤技術,以便能製作特殊效果。
像OpenGL這類的繪圖API並沒有在單純的光線追蹤渲染器中採用主要光線概念來決定可視性。此功能是透過掃描線光柵演算法來執行,它是發生在場景空間座標系統,在此系統中,光線必須在世界空間中被投射出來。解決此問題的一種方式是,採用被稱為延遲著色的多步驟(Multipass)渲染技巧(圖5)。
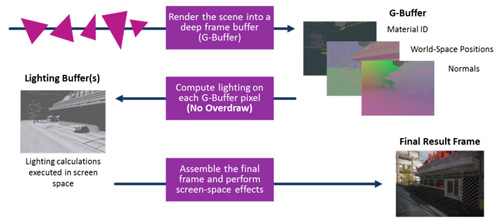 |
| 圖5 利用延遲著色的新型遊戲引擎 |
此技巧常用於遊戲引擎的Runtime中,第一步驟是執行可視性決定,接下來第二步驟是執行附加在可視幾何上的著色器程式。此技巧的目標是降低著色物件的額外負擔,這些物件通常是看不見的,但它也能被用來在混合系統中來投射起始光線。由於第一步驟之後儲存的中間訊息包括世界空間座標及表面法線向量等資料,所以著色器程式已具備所有投射起始光線所需的訊息(圖6)。
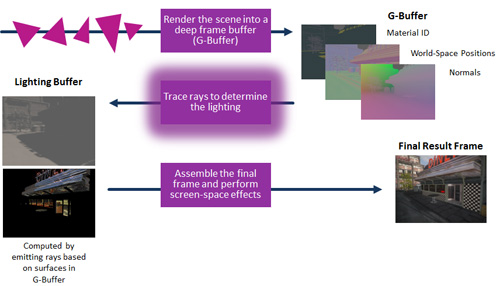 |
| 圖6 遊戲引擎中的混合式渲染,利用延遲著色G-緩衝器。 |
此方法的效益在於只有可見畫素才會投射光線,但這也表示開發人員僅能選擇特定物件來投射光線,因此能輕鬆地控制如何使用特效,以及光線應用在什麼地方。它還非常適用於現有的遊戲引擎Runtime,因此工作流程能保持不變,同時還能保存所有對現有遊戲資源的投資。這樣的控制流程意味著,有可能漸進地將資產從增量式技巧轉移到光線追蹤技巧,為開發人員帶來順利移轉所需的靈活性(圖7?8)。
 |
| 圖7 傳統的光柵式渲染技巧不能簡單且準確地模擬光線傳輸 |
 |
| 圖8 無需額外成本,PowerVR光線追蹤GPU能提供超真實感的陰影、反射和透明度。 |
使用光線追蹤 挖掘新穎功能
光線追蹤在遊戲中最顯著的應用是利用Runtime產生的陰影和反射來建立完全動態的光線。由於能將陰影和反射也納入真實感和互動性的增強之中,因此能免於取樣偽影的影響,以及移除對玩家移動自由度的限制。增強的移動自由度是實現虛擬和擴增實境等應用的重要技術,並能為線上購物等領域開啟全新的應用方式。
此外,現在開發人員可以擁有過去其他利用傳統技巧可能無法實現,或是品質太低的功能。這些功能的一些範例包括:
簡單地在視點和渲染場景間放置一個適當特性的透鏡,就能產生景深、魚眼圖或球面像差等效果(若需要,可做為修正之用)。
近來熱門的運算攝影技巧,例如光場渲染,使用者須要產生多個不同視角的影像;若是立體渲染,須用到兩個影像,更多影像則用於多視角柱狀透鏡顯示。掃描線渲染會須要多次轉換幾何到不同檢視區域的額外負擔,而光線追蹤能重複使用這些轉換結果,並輕鬆地從每個所需的視角投射光線(圖9)。
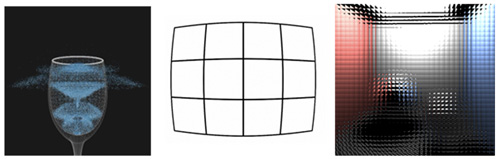 |
| 圖9 利用光線追蹤技術可開發物理、透鏡扭曲修正和柱狀透鏡顯示渲染等功能。 |
能夠透過變換投射在場景的每個區域的光線數量來實現,取決於此場景是否是主要的注意焦點。
這並不能算是一種繪圖技巧,但能用來提升遊戲中角色的人工智慧,透過讓它們投射光線,以便能建立其對其他角色或光源的可視性。另一種使用方式是,投射光線還能被用來開發撞擊偵測系統。
本文中介紹的硬體光線追蹤解決方案已經就緒,適用於開發包括遊戲機,和其他消費性裝置如手持和行動裝置所用的晶片,並能滿足其成本與功耗需求。此解決方案具備的效能與特性,再加上低風險的移轉路徑,對於想要簡化內容創作流程,但又能製作更令人驚豔、更具真實感遊戲的開發人員來說,是深具吸引力的。隨著此技術將於未來幾個月推出,光線追蹤應用將能很快地在市場上實現。