










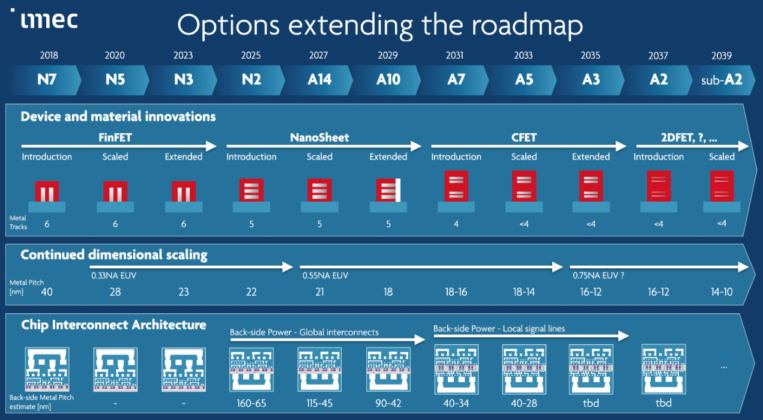












根據最新公布的MLPerf基準測試結果,輝達(NVIDIA)的合作夥伴目前提供用於訓練人工智慧(AI)的GPU加速系統,其速度較任何系統更快。七間公司在最新一輪的產業基準測試中,提交至少十多套市售系統進行測試,其中大多為NVIDIA認證系統。NVIDIA與戴爾(Dell)、富士通(Fujitsu)、技嘉(GIGABYTE)、浪潮(Inspur)、聯想(Lenovo)、寧暢(Nettrix)及美超微(Supermicro)共同展示了使用NVIDIA A100 Tensor核心GPU訓練神經網路。
與2020年的成績相比,NVIDIA的效能表現提升了3.5倍。針對需要使用龐大運算資源的大規模作業,從4,096個GPU中集結資源,較任何其他參與測試的產品都還要更多。
MLPerf的測試成果讓用戶能在充分瞭解的情況下進行購買決策,這項測試基準以AI作業負載和場景為基礎,涵蓋電腦視覺、自然語言處理、推薦系統、強化學習等,而訓練基準則聚焦於用戶最為關心的事情,也就是訓練一個全新AI模型所需耗費的時間。
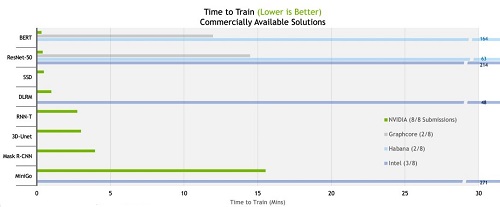
根據最新的MLPerf測試結果,NVIDIA AI平台在商用AI超級電腦類別的所有八項基準測試中以最短的時間訓練模型,創下了效能記錄。根據最新的TOP500排名,在當今世界上最快的商用AI超級電腦 Selene上進行大規模測試。Selene超級電腦與排行榜上其它十多套系統一樣,皆採用NVIDIA DGX SuperPOD架構。
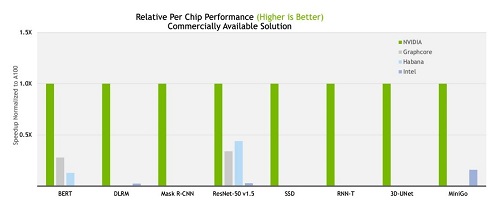
整體來說,下方的測試結果顯示我們的效能在兩年半內提升了 6.5 倍,這證明了可以在 GPU、系統和軟體的全堆疊(full-stack) NVIDIA平台上進行作業。
MLPerf結果展示了各種基於NVIDIA的AI平台,以及許多創新系統的效能,包含從入門的邊緣伺服器到搭載數千個GPU的AI超級電腦。參與最新基準測試的近二十家雲端服務供應商和OEM廠商,NVIDIA的七個合作夥伴名列其中,其本地端的產品或計畫採用NVIDIA A100 GPU的雲端執行個體、伺服器和PCIe卡中,包括近40個NVIDIA認證系統。
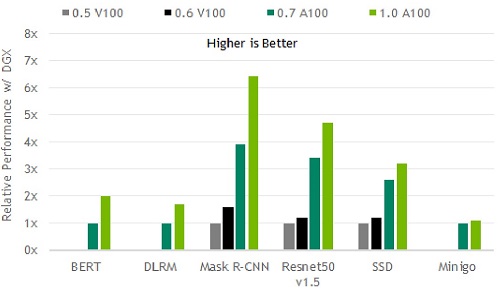
此外,大規模測試使用NVIDIA SHARP,該軟體可以整合網路交換器中的多項資料傳輸作業、減少網路流量與等待CPU處理的時間。結合CUDA Graphs與SHARP,使得資料中心可以運用破紀錄的GPU數量來進行訓練工作。這是如自然語言處理等許多領域所需要使用到的運算能力,在這些領域裡的AI模型規模持續成長,其包含數十億個參數。其他優勢包含最新的A100 GPU將記憶體頻寬增加近30%,達到每秒超過2terabytes(TB)的記憶體頻寬。





