









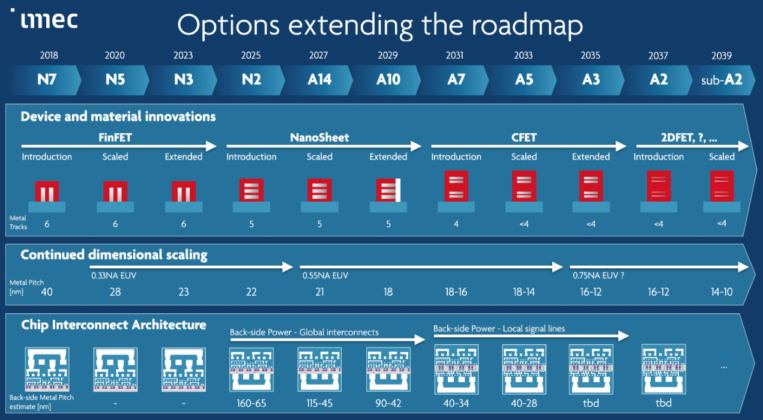



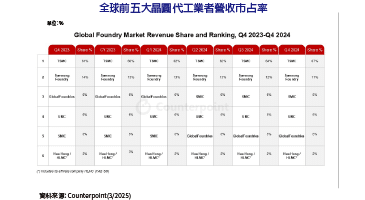
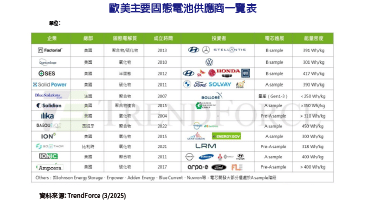




輝達(NVIDIA)併購Arm的起手勢終於明朗就是跨足-CPU。今年GTC宣布推出首個採用Arm Nerverse超算微架構的資料中心中央處理器(CPU),藉由新一代頻寬高達900GB/s的NVLink,NVIDIA Grace得以在多個CPU與GPU之間共享資料與記憶體,突破現行GPU受制PCIe頻寬難以高速存取系統記憶體的限制,針對人工智慧(AI)與高效能運算作業負載的效能宣稱可達當今最快之伺服器的十倍。

一直以來在資料中心高效能運算都與Intel、AMD合作的NVIDIA,在獲得Arm架構奧援之後,正式揮軍超級電腦高效能運算領域,NVIDIA Grace CPU旨在滿足應用程式的運算需求,包括自然語言處理、推薦系統與 AI 超級運算,由於這些應用必須分析龐大的資料集,因此需要快速的運算效能與大量的記憶體。Grace CPU整合節能的Arm CPU核心與創新的低功率記憶體次系統,達到高效能且節能的設計。
NVIDIA 創辦人暨執行長黃仁勳在2021年CTC Keynote演講表示,AI與資料科學正在推進當今電腦架構的極限,因為要處理的資料量多到無法想像。NVIDIA採用授權的Arm IP打造出專為大型AI與高效能運算設計的Grace CPU。結合GPU與DPU,Grace成為NVIDIA第三個基礎運算技術,以及重新架構資料中心並推進AI的能力。NVIDIA現在是提供三種晶片的公司,正式叫板Intel與AMD占據的高效能運算處理器市場。

Grace是具高度特定性的處理器,專為如訓練超過一兆個參數的次世代自然語言處理模型的作業負載所設計。一套基於Grace架構的系統與NVIDIA GPU緊密結合,將提供較當今基於 x86 CPU運行的最頂尖NVIDIA DGX架構系統,十倍的效能提升。
NVIDIA認為,預計絕大多數的資料中心將繼續由現有的CPU提供服務,而為紀念美國電腦程式設計先驅Grace Hopper而命名的Grace CPU,將服務特定的運算領域。瑞士國家超級運算中心(CSCS)與美國能源部的洛斯阿拉莫斯國家實驗室(Los Alamos National Laboratory),率先宣布計劃打造採用Grace的超級電腦並計劃於 2023 年,讓採用 Grace 並由慧與科技(Hewlett Packard Enterprise)所打造的超級電腦正式上線,以支援國家級的科學研究。
由於資料量與AI模型大小呈指數成長,當今最大型的AI模型包含數十億個參數,且每兩個半月就會增加一倍。訓練這些模型需要一個能與GPU緊密結合的全新CPU,才能消除系統瓶頸。NVIDIA利用Arm資料中心架構的彈性來打造Grace。
Grace導入第四代NVIDIA NVLink互聯技術,可以在Grace CPU與NVIDIA GPU間,提供900GB/s連結傳輸速度,Grace也將採用LPDDR5x記憶體次系統,與DDR4記憶體相比,提供兩倍的頻寬以及十倍的能源效率。此外,全新的架構利用單一記憶體位址空間,提供統一的快取記憶體一致性,並結合系統與高頻寬記憶體(HBM)GPU,簡化可編程性。NVIDIA Grace CPU預計將於2023年年初上市。





